Two-sided matching with time preferences

Standard matching mechanisms work well for two-sided preferences. A classical example is Gale-Shapley deferred acceptance algorithm, in which two sets of agents make preference rankings regarding each other. The greatest advantage of the algorithm is that it is efficient, and every agent gets a match. However, what if we want to matchtwo sets of agents, say students and tutors, who have preferences with respect to time slots and not each other?
I claim that we can tweak DA mechanism to make this matching, so that no one is left out. To do that, we have to create an availability matrix from our data. This matrix consists of zeros and ones, where time slots that match both a student and a teacher, are marked with 1. Below is an example availability matrix:

As you might have noticed, it is very easy to convert any Doodle output to this matrix. Now, this matrix will serve as a preference ordering for our algorithm. In other words, a match in required time slots, marked by 1, is more preferrable than no match, marked by 0, but the latter is not completely ruled out. The alogrithm works as follows:
- Every unmatched student submits to any tutor.
- Every tutor says yes if she is (a) idle and (b) (i.e. the allocation matrix for the matching cell is higher than the current value)
- As soon, as some tutor says yes, the student ends the round and next student starts submission process.
- The next round starts where only unmatched students go through steps 1-3.
- When some critical number of iterations is reached, new rounds start where in step 2, tutors will also accept students with zero time slot match.
- The process stops when all students are matched to tutors.
The code representation for this is as follows:
allocation # demonstrate the allocation matrix
# now, proceed to actual matching:
POP <- nrow(allocation)
result <- matrix(0,POP,POP) # create an empty matrix
iter <- 0
while(prod(rowSums(result))==0){# do, while unmatched students still remain
iter <- iter + 1
for(i in 1:POP){# for all students
if(sum(result[i,])==0){# if a student is unmatched
for(j in 1:POP){ # search all tutors
critical.value <- ifelse(iter>MAX.ITERATIONS,0,1) # after MAX.ITERATIONS, just gives up and matches even if time slots are not suitable
if(sum(result[,j])==0 & allocation[i,j]>=critical.value){ # if a tutor is idle and the time slots match (or if mechanism gives up)
result[i,j]=1 # make a match
break # stop round for student i
}
}
}
}
}
result # rows refer to students and columns refer to tutors
This returns the following result matrix:

Great! We are done here.
Bonus
As a bonus I include a matching code for creating the availability matrix. First of all, create the following two dataframes for tutors and students:
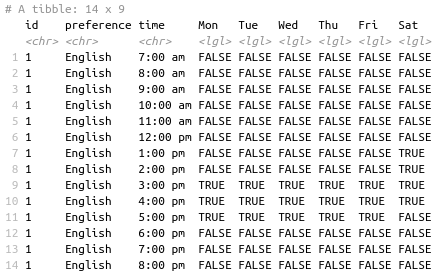
Once you have these for every agent type, it is very easy to compare their matching hours:
hours.matched <- sum(tutee[,4:9]==tutor[,4:9] & tutee[,4:9]==TRUE)
Voila! We are done here… but if you are too busy to create your own availability matrix, here is the code:
# create an empty matrix : rows are students and columns are tutors
allocation <- matrix(0,nrow=length(unique(tutees$id)),ncol=length(unique(tutors$id)))
# I called it allocation and not availability matrix. Get used to it, life is difficult.
for(i in unique(tutees$id)){# for every student:
tutee <- tutees %>% filter(id==i)
mypref <- tutee$preference[1]
tutors.suitable <- NA
if(mypref=="Indifferent"){
tutors.suitable <- tutors
}else{
tutors.suitable <- tutors %>% filter(preference==mypref | preference=="Indifferent")
}
for(j in unique(tutors.suitable$id)){#look for tutors with matching subject
tutor <- tutors %>% filter(id==j)
hours.matched <- sum(tutee[,4:9]==tutor[,4:9] & tutee[,4:9]==TRUE)
if(hours.matched>=HOURS.REQUIRED){# and if number of hour intersections is higher than required
allocation[as.integer(i),as.integer(j)] <- 1 # mark the cell
}
}
}
allocation # demonstrate the allocation matrix
One final bonus
Fine, if you really don’t have time, here is the code that transforms time slots in columns (probably obtained from your questionnaire), then you can convert them to the format I suggested above, as follows:
tutors <- tutors %>%
pivot_longer(cols = c(`7:00 am`:`8:00 pm`),names_to = "time",values_to="day")
tutors <- tutors %>%
mutate(Mon=grepl("Monday",day),
Tue=grepl("Tuesday",day),
Wed=grepl("Wednesday",day),
Thu=grepl("Thursday",day),
Fri=grepl("Friday",day),
Sat=grepl("Saturday",day),) %>% select(-day)
OK, now we are really done. Good luck and follow me on Twitter: @ravshansk.
Explore my other posts

Modeling organizations
Herbert Simon famously wrote that if a visitor came from Mars they would call our economy an “organization economy,” not a “market economy,” because most economic activity happens inside firms,...

A no-nonsense guide to frontend for backend developers
Introduction Absolute basics Client-side vs. Server-side Components Frontend libraries Conclusion